
영권's
13주차 과제: I/O 본문
목표
자바의 Input과 Ontput에 대해 학습하세요.
학습할 것 (필수)
- 스트림 (Stream) / 버퍼 (Buffer) / 채널 (Channel) 기반의 I/O
- InputStream과 OutputStream
- Byte와 Character 스트림
- 표준 스트림 (System.in, System.out, System.err)
- 파일 읽고 쓰기
I/O 입출력
입출력이란?
입출력(I/O)란 Input과 Output의 약자로 입력과 출력, 간단히 입출력이라 한다.
입출력은 컴퓨터 내부 또는 외부 장치와 프로그램간의 데이터를 주고 받는 것을 말한다.
- 키보드로부터 데이터를 입력
- System.out.println()을 이용해 화면에 출력
스트림(stream)
자바에서 어느 한 쪽에서 다른 쪽으로 데이터를 전달하려면, 두 대상을 연결하고 데이터를 전송할 수 있는 무언가가 필요한데, 이것을 스트림(stream)이라 정의한다.
람다와 스트림에서 얘기하는 스트림과 같은 용어를 사용하지만, 다른 개념이다.
스트림이란 데이터를 운반하는데 사용되는 연결 통로이다.
스트림은 연속적인 데이터의 흐름을 물에 비유해서 붙여진 이름인데, 여러가지로 유사한 점이 많다.
- 물이 한 쪽 방향으로만 흐르는 것과 같이 스트림은 단방향통신만 가능하기 때문이다.
즉, 하나의 스트림으로 입력과 출력을 동시에 처리할 수 없다는 것이다.

입력과 출력을 동시에 처리하기 위해서는 입력을 위한 입력 스트림(input stream)과 출력을 위한 출력 스트림(output stream), 모두 2개의 스트림이 필요하다.
- 스트림은 먼저 보낸 데이터를 먼저 받게 되어 있으며
- 중간에 건너뜀 없이 연속적으로 데이터를 주고 받는다.
- 큐(Queue)와 같은 FIFO(First In First Out) 구조로 되어 있다고 생각하면 이해하기 쉽다.
스트림 클래스는 크게 두 종류로 구분된다.
하나는 바이트(Byte)기반이고, 다른 하나는 문자(Character)기반 스트림이다.
바이트 기반 스트림은 그림, 멀티미디어, 문자 등 모든 종류의 데이터를 받고 보낼 수 있으나, 문자 기반 스트림은 오로지 문자만 받고 보낼 수 있도록 특화 되어 있다.
바이트 기반 스트림과 문자 기반 스트림은 최상위 클래스에 따라서 다음과 같이 구분된다.
| 구분 | 바이트 기반 스트림 | 문자 기반 스트림 | ||
| 입력 스트림 | 출력 스트림 | 입력 스트림 | 출력 스트림 | |
| 최상위 클래스 | InputStream | OutputStream | Reader | Writer |
| 하위 클래스(예) | XXXInputStream (FileInputStream) |
XXXOutputStream (FileOutputStream) |
XXXReader (FileReader) |
XXXWriter (FileWriter) |


버퍼
그렇다면 버퍼는 무엇일까?
일반적인 입출력과 다르게, 한곳에 저장시킨뒤, 한번에 보내는 방식을 뜻한다.
- byte, char, int 등 기본 데이터 타입을 저장할 수 있는 저장소로서, 배열과 마찬가지로 제한된 크기(capacity) 에 순서대로 데이터를 저장한다.
- 버퍼는 데이터를 저장하기 위한 것이지만, 실제로 버퍼가 사용되는 것는 채널을 통해서 데이터를 주고 받을 때 쓰인다.
- 채널을 통해서 소켓, 파일 등에 데이터를 전송할 때나 읽어올 때 버퍼를 사용하게 됨으로써 가비지량을 최소화 시킬 수 있게 되며, 이는 가바지 콜렉션 회수를 줄임으로써 서버의 전체 처리량을 증가시켜준다.
채널
우리가 알고 있듯이 TV채널과 이 채널은 같은 뜻 일까?
채널은 입력 과 출력을 동시에 할 수 있다고 한다.
즉, 비동기적으로 입출력이 가능하다는 이야기 같다.
- 데이터가 통과하는 쌍방향 통로이며, 채널에서 데이터를 주고 받을 때 사용 되는 것이 버퍼이다.
- 채널에는 소켓과 연결된 SocketChannel, 파일과 연결된 FileChannel, 파이프와 연결된 Pipe.SinkChannel 과 Pipe.SourceChannel 등이 존재하며, 서버소켓과 연결된 ServerSocketChannel 도 존재한다.

그림은 동기식처럼 보이지만 기술상의 문제로 비동기처럼 보여주기는 어려울것 같아 이런식으로 표현되었다.
바이트 기반 스트림 - InputStream, OutputStream
스트림은 바이트단위로 데이터를 전송하며 입출력 대상에 따라서 다음과 같은 입출력 스트림이 있다.
| 입력 스트림 | 출력 스트림 | 입출력 대상의 종류 |
| FIleInputStream | FileOutputStream | 파일 |
| ByteArrayInputStream | ByteArrayOutputStream | 메모리(Byte배열) |
| PipedInputInputStream | PipedOutputStream | 프로세스(프로세스간 통신) |
| AudioInputStream | AudioOutputStream | 오디오 장치 |
어떠한 대상에 대해 작업을 할 것인지,
입력을 할 것인지 출력을 할 것인지에 따라 해당 스트림을 선택해서 사용할 수 있다.
위 입출력 스트림은 각각 InputStream과 OutputStream의 자손들이며, 각각 읽고 쓰는데 필요한 추상 메서드를 자신에 맞게 구현해놓은 구현체이다.
입출력 스트림의 부모 InputStream, OutputStream
InputStream은 바이트 기반 입력 스트림의 최상위 클래스로 추상 클래스이다.
모든 바이트 기반 입력 스트림은 이 클래스를 상속 받아서 만들어진다.
InputStream 클래스에는 바이트 기반 입력 스틤이 기본적으로 가져야 할 메서드가 정의되어 있다.
| 리턴 타입 | 메서드 | 설명 |
| int | read() | 입력 스트림으로 부터 1바이트를 읽고 읽은 바이트를 리턴한다. 더이상 입력 스트림으로부터 바이트를 읽을 수 없다면 -1을 리턴 |
| int | read(byte[] b) | 입력 스트림으로 부터 읽은 바이트들을 매개값으로 주어진 바이트 배열 b에 저장하고 실제로 읽은 바이트 수를 리턴한다. 더이상 입력 스트림으로부터 바이트를 읽을 수 없다면 -1을 리턴 |
| int | read(byte[] b,int off, int len) | 입력 스트림으로 부터 len개의 바이트만큼 읽고 매개값으로 주어진 바이트배열 b[off] 부터 len개 까지 저장한다. 그리고 실제로 읽은 바이트 수인 len개를 리턴한다. 만약 len를 모두 읽지 못하면 실제로 읽은 바이트 수를 리턴한다. |
| void | close() | 사용한 시스템 자원을 반납하고 입력 스트림을 닫는다. |
OutputStream은 바이트 기반 출력 스트림의 최상위 클래스로 추상 클래스이다.
모든 바이트 출력 스트림 클래스는 이 클래스를 상속받아서 만들어진다.
OutputStream 클래스에는 모든 바이트 기반 출력 스트림이 기본적으로 가져야 할 메서드가 정의되어 있다.
| 리턴 타입 | 메서드 | 설명 |
| void | write(int b) | 출력 스트림으로 1바이트를 보낸다(b의 끝 1바이트) |
| void | write(byte[] b) | 출력 스트림으로 주어진 바이트 배열 b의 모든 바이트를 보낸다. |
| void | write(byte[] b, int off, int len) | 출력 스트림으로 주어진 바이트 배열 b[off]부터 len개까지의 바이트를 보낸다. |
| void | flush() | 버퍼에 잔류하는 모든 바이트를 출력한다. |
| void | close() | 사용한 시스템 자원들 반납하고 출력 스트림을 닫는다. |
InputStream과 OutputStream에 정의된 읽기와 쓰기를 수행하는 메서드
read()의 반환타입이 byte 가 아닌 int인 이유는 read()의 반환값의 범위가 0~255와 -1 이기 떄문이다.
위 Input, OutputStream의 메서드 사용법만 잘 알고 있다면, 데이터를 읽고 쓰는 것은 대상의 종류에 관계 없이 간단한 일이 될 것이다.
- InputStream의 read()와 OutputStream의 write(int b) 는 입출력의 대상에 따라 읽고 쓰는 방법이 다를 것이기 때문에, 각 상황에 알맞게 구현하라는 의미의 추상 메서드로 정의되어 있다.
- read()와 write(int b)를 제외한 나머지 메서드들은 추상메서드가 아니니까 굳이 추상메서드인 read()와 write(int b) 를 구현하지 않아도 이들을 사용하면 될 것이라 생각할 수 있겠지만,
- 사실 추상메서드인 read()와 write(int b)를 이용해서 구현한 것들임으로 read()와 write(int b)가 구현되어 있지 않으면 이들은 아무런 의미가 없다.
문자기반 스트림 - Reader, Write
바이트기반의 입출력 스트림의 단점(1byte → 2byte)을 보완하기 위해 문자기반의 스트림을 제공한다.
문자데이터를 입출력할 때는 바이트기반 스트림 대신 문자 기반 스트림을 사용하도록 하자.
InputStream → Reader
OutputStream → Writer
Reader는 문자 기반 입력 스트림의 최상위 클래스로 추상 클래스이다.
모든 문자 기반 입력 스트림은 이 클래스를 상속받아서 만들어진다.
Reader 클래스에는 문자기반 입력 스트림이 기본적으로 가져야 할 메서드가 정의되어 있다.
다음은 Reader 클래스의 주요 메서드이다.
| 메서드 | 설명 | |
| int | read() | 입력 스트림으로부터 한 개의 문자를 읽고 리턴한다. |
| int | read(char[] cbuf) | 입력 스트림으로부터 읽은 문자들을 매개값으로 주어진 문자 배열 cbuf에 저장하고 실제로 읽은 문자 수를 리턴한다. |
| int | read(char[] cbuf, int off, int len) | 입력 스트림으로부터 len개의 문자를 읽고 매개값으로 주어진 문자 배열 cbuf[off]부터 len개까지 저장한다. 그리고 실제로 읽은 문자 수인 len개를 리턴한다. |
| void | close() | 사용한 시스템 자원을 반납하고 입력 스트림을 닫는다. |
Writer는 문자 기반 출력 스트림의 최상위 클래스로 추상 클래스이다.
모든 문자 기반 출력 스트림 클래스는 이 클래스를 상속 받아서 만들어진다.
Writer 클래스가 가져야할 기본적인 메서드
| 리턴 타입 | 메서드 | 설명 |
| void | write(int c) | 출력 스트림으로 주어진 한 문자를 보낸다.(c의 끝 2바이트) |
| void | write(char[] cbuf) | 출력 스트림으로 주어진 문자 배열 cbuf의 모든 문자를 보낸다. |
| void | write(char[] cbuf, int off, int len) | 출력 스트림으로 주어진 문자 배열 cbuf[off]로부터 len개까지의 문자를 보낸다. |
| void | write(String str) | 출력 스트림으로 주어진 문자열을 전부 보낸다. |
| void | write(String str, int off, int len) | 출력 스트림으로 주어진 문자열 off 순번부터 len개까지의 문자를 보낸다. |
| void | flush() | 버퍼에 잔류하는 모든 문자열을 출력한다. |
| void | close() | 사용한 시스템 자원을 반납하고 출력 스트림을 닫는다. |
콘솔 입출력
표준입출력은 콘솔을 통한 데이터 입력과 콘솔로의 데이터 출력을 의미한다.
자바에서는 표준 입출력(standard I/O)를 위해 3가지 입출력 스트림을 제공한다.
- System.in
- System.out
- System.err
이들은 자바 어플리케이션의 실행과 동시에 사용할 수 있게 자동적으로 생성되기 때문에 개발자가 별도로 스트림을 생성하는 코드를 작성하지 않아도 된다.
System.in // 콘솔로부터 데이터를 입력받는데 사용
System.out // 콘솔로 데이터를 출력하는데 사용
System.err // 콘솔로 데이터를 출력하는데 사용

System 클래스를 살펴보면
- in, out, err는 System클래스에 선언된 클래스변수(static) 이다.

-> 선언부만 봐서는 in, out, err의 타입이 InputStream과 PrintStream이지만 실제로는 버퍼를 이용하는 BufferedInputStream과 BufferedOutputStream의 인스턴스를 사용한다.

package java.lang;
public final class System {
...
// Initialize the system class. Called after thread initialization.
private static void initializeSystemClass() {
...
FileInputStream fdIn = new FileInputStream(FileDescriptor.in);
FileOutputStream fdOut = new FileOutputStream(FileDescriptor.out);
FileOutputStream fdErr = new FileOutputStream(FileDescriptor.err);
setIn0(new BufferedInputStream(fdIn));
setOut0(newPrintStream(fdOut, props.getProperty("sun.stdout.encoding")));
setErr0(newPrintStream(fdErr, props.getProperty("sun.stderr.encoding")));
...
}
...
}
보조 스트림
보조 스트림이란 다른 스트림과 연결되어 여러가지 편리한 기능을 제공해주는 스트림을 말한다.
보조 스트림을 필터(filter) 스트림이라고도 하는데, 이는 보조 스트림의 일부가 FilterInputStream,FilterOutputStream의 하위 클래스이기 때문이다.
하지만 다른 보조 스트림은 이 클래스들을 상속 받지 않기 때문에 필터 스트림대신 보조 스트림이라고 한다.
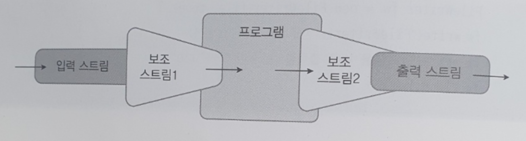
보조 스트림을 생성할 때는 자신이 연결될 스트림을 다음과 같이 생성자의 매개 값으로 받는다.
보조스트림 변수 = new 보조스트림(연결스트림)예를 들어 콘솔 입력 스트림을 문자 변환 보조 스트림인 InputStreamReader에 연결하는 코드는 다음과 같다.
InputStream is = System.in;
InputStreamReader reader = new InputStreamReader(is);
다음 그림을 보면 보조 스트림은 또 다른 보조 스트림에도 연결되어 체인을 구성할 수 있다.

예를 들어 문자 변환 보조 스트림인 InputStreamReader를 다시 성능 향상 보조 스트림인 BufferedRead에 연결하는 코드는 다음과 같다.
InputStream is = System.in;
InputStreamReader reader = new InputStreamReader(is);
BufferedReader br = new BufferedReader(reader);
성능 향상 보조 스트림
프로그램의 실행 성능은 입출력이 가장 늦은 장치를 따라간다.
CPU와 메모리가 아무리 뛰어나도 하드 디스크의 입출력이 늦어지면 프로그램의 실행 성능은 하드 디스크의 처리 속도에 맞춰진다.
네트워크로 데이터를 전송할 때도 마찬가지다.
스트림의 기능을 보완하기 위해 보조스트림이라는 것이 제공된다.
프로그램이 입출력 소스와 직접 작업하지 않고 중간에 메모리 버퍼(buffer)와 작업함으로써 실행 성능을 향상 시킬 수 있다.

보조스트림은 실제 데이터를 주고받는 스트림이 아니기 때문에 데이터를 입출력할 수 있는 기능은 없지만, 스트림의 기능을 향상 시키거나 새로운 기능을 추가할 수 있다.
즉, 스트림을 먼저 생성한 다음에 이를 이용해 보조스트림을 생성해서 활용한다.
Buffer 를 사용하면 좋은 이유
속도가 왜 빨라질까?
- 모아서 보내면 왜 빨라질까?
- 한 바이트씩 바로바로 보내는 것이 아니라 버퍼에 담았다가 한번에 모아서 보내는 방법인데 왜 이렇게 하는 것이
- 입출력 횟수가 포인트 이다.
- 단순히 모아서 보낸다고 이점이 있는 것이 아니다 → 시스템 콜의 횟수가 줄어들었기 때문에 성능상 이점이 생기는 것이다
- OS 레벨에 있는 시스템 콜의 횟수 자체를 줄이기 때문에 성능이 빨라지는 것이다.
예시)
물을 떠와라 → 물을 한 모금 씩 떠와라
- 매번 한모금 먹고 주방 갔다오고 또 먹고 갔다오고 반복..
물을 떠와라 → 물을 한 컵씩 떠와라
- 한 컵이 다 마실 때 까지 물을 마실 수 있지,
보조스트림 그 자체로 존재하는 것이 아니라 부모/자식 관계를 이루고 있는 것임으로,
보조스트림 역시 부모의 입출력 방법과 같다.
BufferedInputStream과 BufferedReader
bufferedInputStream은 바이트 입력 스트림에 연결되어 버퍼를 제공해주는 보조 스트림이고, BufferedReader는 문자 입력 스트림에 연결되어 버퍼를 제공해주는 보조 스트림이다.
BufferedInputStream과 BufferedReader는 입력 소스로부터 자신의 내부 크기만큼 데이터를 미리 읽고 버퍼에 저장해 둔다.
프로그램은 외부의 입력 소스로부터 직접 읽는 대신 버퍼로부터 읽음으로써 읽기 성능이 향상된다.
BufferedInputStream bis = new BufferedInputStream(바이트입력스트림);
BufferedReader br = new BufferedReader(문자입력스트림);
BufferedInputStream과 BufferedReader 보조 스트림은 다음과 같이 생성자의 매개값으로 준 입력 스트림과 연결되어 default 8192 내부 버퍼사이즈를 가지게 된다.
BufferedInputStream은 8192 바이트가, BufferedReader는 문자 최대 8192 문자가 저장될 수 있다.
InputStream 또는 Reader와 데이터를 읽어 들이는 방법은 동일하다.
import java.io.*;
public class BufferedInputStreamExample {
public static void main(String[] args) throws IOException {
long start = 0;
long end = 0;
FileInputStream fis1 = new FileInputStream("C:\\Users\\youngkwon\\Desktop\\dog.jpg");
start = System.currentTimeMillis();
//start = System.nanoTime();
while (fis1.read() != -1) {
}
end = System.currentTimeMillis();
System.out.println("사용하지 않았을 때 : " + (end - start) + "ms");
fis1.close();
FileInputStream fis2 = new FileInputStream("C:\\Users\\youngkwon\\Desktop\\dog.jpg");
BufferedInputStream bis = new BufferedInputStream(fis2);
start = System.currentTimeMillis();
while (bis.read() != -1) {
}
end = System.currentTimeMillis();
System.out.println("사용했을 때 : " + (end - start) + "ms");
fis2.close();
}
}

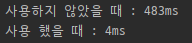
BufferedInputStream을 사용했을때와 사용하지 않았을 때의 실행 결과이다.
BufferedReader는 readLine() 메서드를 추가적으로 더 가지고 있는데, 이 메서드를 이용하면 캐리지리턴(\ㄱ)과 라인피드(\n)로 구분된 행 단위의 문자열을 한꺼번에 읽을 수 있다.
BufferedOutputStream과 BufferedWriter
BufferedOutputStream은 바이트 출력 스트림에 연결되어 버퍼를 제공해주는 보조 스트림이고, BufferedWriter는 문자 출력 스트림에 연결되어 버퍼를 제공해주는 스트림이다.
BufferedOutputStream과 BufferedWriter는 프로그램에서 전송한 데이터를 내부에 쌓아 두었다가 버퍼가 꽉차면, 버퍼의 모든 데이터를 한번에 보낸다.
프로그램 입장에서 보면 직접 데이터를 보내는 것이 아니라, 메모리 버퍼로 데이터를 고속 전송하기 때문에 실행 성능이 향상되는 효과를 얻게 된다.
BufferedOutputStream bos = new BufferedOutputStream(바이트출력스트림);
BufferedWriter bw = new BufferedWriter(문자출력스트림);
BufferedOutputStream과 BufferedWriter로 데이터를 출력하는 방법은 OutputStream 또는 Writer와 동일하다.
주의할 점은 버퍼가 가득 찼을 때만 출력을 하기 때문에 마지막 자투리 데이터 부분이 목적지로 가지 못하고 버퍼에 남아있을 수 있다.
그래서 마지막 출력 작업을 마친 후에는 flush()메서드를 호출하여 버퍼에서 잔류하고 있는 데이터를 모두 보내도록 해야한다.
다음은 파일 복사 예제로 BufferedOutputStream을 사용했을 때와 사용하지 않았을 댸의 프로그램 성능 차이를 보여준다.
import java.io.*;
public class BufferedOutputStreamExample {
public static void main(String[] args) throws IOException {
FileInputStream fis = null;
FileOutputStream fos = null;
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
int data = -1;
long start = 0;
long end = 0;
fis = new FileInputStream("C:\\Users\\youngkwon\\Desktop\\dog.jpg");
bis = new BufferedInputStream(fis);
fos = new FileOutputStream("C:\\Users\\youngkwon\\Desktop\\test\\dog.jpg");
start = System.currentTimeMillis();
while ((data = bis.read()) != -1){
fos.write(data);
}
fos.flush();
end = System.currentTimeMillis();
fos.close();
bis.close();
fis.close();
System.out.println("사용하지 않았을 때 : "+ (end - start) + "ms");
fis = new FileInputStream("C:\\Users\\youngkwon\\Desktop\\dog.jpg");
bis = new BufferedInputStream(fis);
fos = new FileOutputStream("C:\\Users\\youngkwon\\Desktop\\test2\\dog.jpg");
bos = new BufferedOutputStream(fos);
start = System.currentTimeMillis();
while ((data = bis.read()) != -1){
bos.write(data);
}
bos.flush();
end = System.currentTimeMillis();
bos.close();
fos.close();
bis.close();
fis.close();
System.out.println("사용 했을 때 : " + (end - start) + "ms");
}
}
파일 읽고 쓰기
File 클래스
IO 패키지 (java.io)에서 제공하는 File 클래스는 파일의 크기, 속성, 이름 등의 정보를 얻어내는 기능과 파일의 생성 및 삭제 기능을 제공한다.
또한, 디렉토리를 생성하고 디렉토리에 존재하는 파일 리스트를 얻어내는 기능이 존재한다.
그러나, 파일의 데이터를 읽고 쓰는 기능은 지원하지 않는다.
파일의 입출력은 스트림을 사용해야 한다.
다음은 C:\Temp 디렉토리의 file.txt 파일을 File객체로 생성하는 코드이다.
File file = new File("C:/Temp/file.txt");
File file = new File("C:\\Temp\\file.txt");| 디렉토리를 구분하는하는 구분자는 OS마다 다르다. 윈도우에서는 "\" 또는 "/" 을 사용할 수 있고, 유닉스와 리눅스에서는 "/"를 사용한다. "\" 을 사용한다면 이스케이프 문자(\\) 로 기술해야 한다. |
File 객체를 생성했다고 해서 파일이나 디렉토리가 생성되는 것은 아니다.
생성자 매개값으로 주어진 경로가 유효하지 않더라도 컴파일 에러나 예외가 발생하지 않는다.
- 생성한 객체를 통해 실제로 파일이나 디렉토리가 있는지 확인하기 위해 exist() 메소드를 호출하여 확인한다.
boolean isExist = file.exist();
// 디렉토리 또는 파일이 파일 시스템에 존재하면 true를 리턴 존재하지 않으면 false를 리턴
exist() 메소드의 결과가 false 인 경우 → createNewFile(), mkdir(), mkdirs() 메서드로 파일 또는 디렉토리를 생성할 수 있다.
| 리턴타입 | 메서드 | 설명 |
| boolean | createNewFile() | 새로운 파일을 생성 |
| boolean | mkdir() | 새로운 디렉토리를 생성 |
| boolean | mkdirs() | 경로상에 없는 모든 디렉토리를 생성 |
| boolean | delete() | 파일 또는 디렉토리 삭제 |
파일 또는 디렉토리가 존재할 경우에는 다음 메서드를 통해 정보를 얻어낼 수 있다.
| 리턴타임 | 메서드 | 설명 |
| boolean | canExecute() | 실행할 수 있는 파일인지 여부 |
| boolean | canRead() | 읽을 수 있는 파일인지 여부 |
| boolean | canWrite() | 수정 및 저장할 수 있는 파일인지 여부 |
| String | getName() | 파일의 이름을 리턴 |
| String | getParent() | 부모 디렉토리를 리턴 |
| File | getParentFile() | 부모 디렉토리를 File 객체로 생성 후 리턴 |
| String | getPath() | 전체 경로를 리턴 |
| boolean | isDirectory() | 디렉토리인지 여부 |
| boolean | isFile() | 파일인지 여부 |
| boolean | isHidden() | 숨김 파일인지 여부 |
| long | lastModified() | 마지막 수정 날짜 및 시간을 리턴 |
| long | length() | 파일의 크기를 리턴 |
| String[] | list() | 디렉토리에 포함된 파일 및 서브 디렉토리 목록 전부를 String 배열로 리턴 |
| String[] | list(FilenameFilter filter) | 디렉토리에 포함된 파일 및 서브디렉토리 목록 중에 FilenameFilter에 맞는 것만 String 배열로 리턴 |
| File[] | listFiles() | 디렉토리에 포함된 파일 및 서브 디렉토리 목록 전부를 File 배열로 리턴 |
| File[] | listFiles(FilenameFilter filter) | 디렉토리에 포함된 파일 및 서브디렉토리 목록 중에 FilenameFilter에 맞는 것만 File 배열로 리턴 |
다음은 Temp디렉토리에 Dir 디렉토리와 file1.txt , file2.txt, file3.txt 파일을 생성하고, Temp 디렉토리에 있는 파일 목록을 출력하는 예제이다.
import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class FileExample {
public static void main(String[] args) throws URISyntaxException, IOException {
File dir = new File("C:\\Users\\youngkwon\\Desktop\\Temp\\dir");
File file1 = new File("C:\\Users\\youngkwon\\Desktop\\Temp\\file1.txt");
File file2 = new File("C:\\Users\\youngkwon\\Desktop\\Temp\\file2.txt");
File file3 = new File(new URI("file:///C:/Users/youngkwon/Desktop/Temp/file3.txt")); // 파일 경로를 URI 객체로 생성해서 매개값을 제공해도 됨.
if (dir.exists() == false) {
dir.mkdirs();
}
if (file1.exists() == false) {
file1.createNewFile();
}
if (!file2.exists()) {
file2.createNewFile();
}
if (!file3.exists()) {
file3.createNewFile();
}
File temp = new File("C:\\Users\\youngkwon\\Desktop\\Temp");
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd a HH:mm");
File[] contents = temp.listFiles();
System.out.println("날짜 시간 형태 크기 이름");
for (File content : contents) {
System.out.println(sdf.format(new Date(content.lastModified())));
if (file1.isDirectory()){
System.out.print("\t<DIR>\t\t\t" + content.getName());
}else{
System.out.print("\t\t\t" + content.length() + "\t" + content.getName());
}
System.out.println();
}
}
}


객체 입출력 보조 스트림(직렬화)
- 자바는 메모리에 생성된 객체를 파일 또는 네트워크로 출력할 수가 있다.
- 객체는 문자가 아니기 때문에 바이트 기반 스트림으로 출력해야한다.
- 객체를 출력하기 위해서는 객체의 데이터(필드값)를 일렬로 늘어선 연속적인 바이트로 변경해야 하는데, 이것을 객체 직렬화(serialization)라고 한다.
- 반대로 파일에 저장되어 있거나 네트워크에서 전송된 객체를 읽을 수도 있는데, 입력 스트림으로부터 읽어들인 연속적인 바이트를 객체로 복원하는 것을 역직렬화(deserialization)라고 한다.
객체에 대해 다시 짚고 넘어가보자.
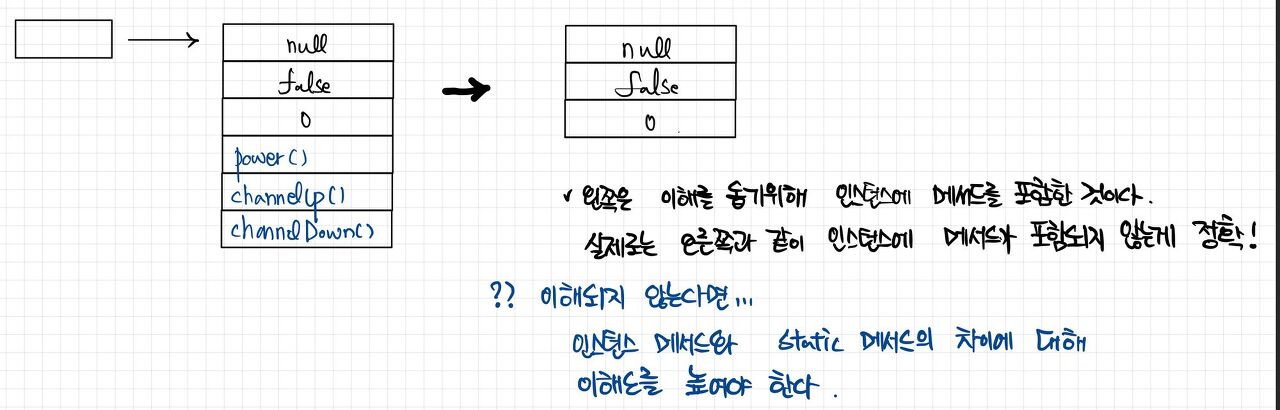
- 객체는 클래스에 정의된 인스턴스변수의 집합이다.
- 객체에는 클래스변수나 메서드가 포함되지 않는다. 객체는 오직 인스턴스 변수들로만 구성되어 있다.
- 표현시에 인스턴스변수와 메서드를 함께 그리곤 했지만, 사실 객체에는 메서드가 포함되지 않는다.
- 인스턴스변수는 인스턴스마다 다른 값을 가질 수 있어야 하기 때문에 별도의 메모리 공간이 필요하지만
- 메서드는 변하는 것이 아니라서 메모리를 낭비해 가면서 인스턴스마다 같은 내용의 코드(메서드)를 포함시킬 이유가 없다.
객체를 저장한다는 것은 바로 객체의 모든 인스턴스변수의 값을 저장한다는 것과 같은 의미이다.
어떤 객체를 저장하고자 한다면, 현재 객체의 모든 인스턴스변수의 값을 저장하기만 하면된다. 그리고 저장했던 객체를 다시 생성하려면, 객체를 생성한 후에 저장했던 값을 읽어서 생성한 객체의 인스턴스변수에 저장하면 되는 것이다.
ObjectInputStream, ObjectOutputStream
자바는 객체를 입출력할 수 있는 도 개의 보조 수트림인 ObjectInputStream과 ObjectOutputStream을 제공한다.
- ObjectOutputStream은 바이트 출력 스트림과 연결되어 객체를 직렬화하는 역할을 하고,
- ObjectInputStream은 바이트 입력 스트림과 연결되어 객체를 역직렬화하는 역할을 한다.
// 바이트 입력 스트림을 직렬화 할 수 있는 스트림으로 바꿈.
ObjectInputStream ois = new ObjectInputStream(바이트 입력 스트림);
// 객체를 직렬화하여 출력 스트림으로 보냄
ois.writeObject(객체);
출처: https://alkhwa-113.tistory.com/entry/IO [기(술) 블로그]
- ObjecOutputStream : 바이트 기반 스트림을 객체를 직렬화하여 출력할 수 있는 스트림으로 만든다.
- writeObject() 로 객체를 직렬화할 수 있다.
// 바이트 출력 스트림을 직렬화 할 수 있는 스트림으로 바꿈.
ObjectOutputStream oos = new ObjectOutputStream(바이트 출력 스트림);
// 읽어온 것을 역직렬화하여 객체에 저장
객체타입 변수 = oos.readObject();
출처: https://alkhwa-113.tistory.com/entry/IO [기(술) 블로그]- ObjectInputStream : 바이트 기반 스트림을 객체를 역직렬화하여 입력할 수 있는 스트림으로 만든다.
- readObject() 로 객체를 역직렬화할 수 있다.
직렬화가 가능한 클래스(Serializable)
- 자바는 Serializable 인터페이스를 구현한 클래스만 직렬화 할 수 있도록 제한하고 있다.
- Serializable 인터페이스는 필드나 메서드가 없는 빈 인터페이스이지만, 객체를 직렬화할 때 private 필드를 포함한 모든 필드를 바이트로 변환해도 좋다는 표시 역할을 한다.
// 직렬화가 가능한 클래스
public class XXX implements Serializable{}
- 객체를 직렬화하면 바이트로 변환되는 것은 필드들이고, 생성자 및 메서드는 직렬화에 포함되지 않는다.
- 따라서 역직렬화할 때에는 필드의 값만 복원된다.
- 하지만 모든 필드가 직렬화 대상이 되는 것은 아니다.
- 필드 선언에 static 또는 transient가 붙어 있을 경우에는 직렬화가 되지 않는다.
public class XXX implements Serializable{
public int field1; // 직렬화 포함
protected int field2; // 직렬화 포함
int field3; // 직렬화 포함
private int field4 // 직렬화 포함
public static int field5; // 직렬화 제외
transient int field6; // 직렬화 제외
}
SerialversionUID 필드
직렬화된 객체를 역직렬화할 때는 직렬화했을 때와 같은 클래스를 사용해야 한다.
클래스 이름이 같더라도 클래스의 내용이 변경되면, 역직렬화는 실패하여 다음과 같은 예외가 발생한다.
java.io.InvalidClassException: XXX; local class incompatible: stream classdesc
serialVersionUID = -91307994... , local class serialVersionUID =-11747258...위 예외 내용은 직렬화할 때와 역직렬화할 때 사용된 클래스의 serialVersionUID가 다르다는 것이다.
- serialVersionUID는 같은 클래스임을 알려주는 식별자 역할을 하는데, Serializable 인터페이스를 구현한 클래스를 컴파일하면 자동적으로 serialVersionUID 정적 필드가 추가된다.
- 문제는 클래스를 재 컴파일하면 serialVersionUID의 값이 달라진다는 것이다.
- 네트워크로 객체를 직렬화하여 전송하는 경우, 보내는 쪽과 받는 쪽이 모두 같은 serialVersionUID를 갖는 클래스를 가지고 있어야 하는데 한쪽에서 클래스를 변경해서 재컴파일하면 다른 serialVersionUID를 가지게 되므로 역직렬화에 실패하게 된다.
만약 불가피하게 수정이 필요하다면 클래스 작성 시 다음과 같이 serialVersionUID를 명시적으로 선언하면 된다.
public class XXX implements Serializable{
static final long serialVersionUID = 정수값;
...
}클래스에 serialVersionUID가 명시적으로 선언되어 있으면 컴파일 시에 serialVersionUID 필드가 추가되지 않기 때문에 동일한 serialVersionUID 값을 유지할 수 있다.
serialVersionUID의 값은 개발자가 임의로 줄 수 있찌만 가능하다면 클래스마다 다른 값을 갖도록 하는 것이 좋다.
그래서 자바든 <JDK 설치경로>\bin 폴더에 serialVersionUID 값을 자동으로 생성시켜주는 serialver.exe 명령어를 제공하고 있다.
실행시키는 방법은 다음과 같다.

참고 : https://mail.codejava.net/java-core/tools/using-serialver-command-examples
writeObject()와 readObject() 메서드
두 클래스가 상속 관계에 있다고 가정해볼때, 부모 클래스가 Serializable 인터페이스를 구현하고 있으면 자식 클래스는 Serializable 을 구현하지 않아도 자식 객체를 직렬화하면 부모 필드 및 자식 필드가 모두 직렬화된다.
하지만 반대로 부모 클래스가 Serializable 인터페이스를 구현하고 있지 않고, 자식만 구현하고 있다면 자식 객체를 직렬화할 때 부모의 필드는 직렬화에서 제외된다.
이 경우 부모 클래스의 필드를 직렬화하고 싶다면 다음 두 가지 방법 중 하나를 선택해야 한다.
- 부모 클래스가 Serializable 인터페이스를 구현하도록 한다.
- 자식 클래스에서 writeObject()와 readObject() 메서드를 선언해서 부모 객체의 필드를 직접 출력시킨다.
첫 번째 방법이 제일 좋은 방법이지만, 부모 클래스의 소스를 수정할 수 없는 경우에는 두번째 방법을 사용해야 한다.
writeObject() 메서드는 직렬화 될 때 자동으로 호출되고, readObject() 메서드는 역직렬화될 때 자동적으로 호출된다.
writeObject()와 readObject() 메서드의 선언 방법
private void writeObject(ObjectOutputStream out) throws IOException{
out.write(부모필드); - 부모 객체의 필드값을 출력
...
out.defaultWriteObject(); - 자식 객체의 필드값을 직렬화
}private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException{
부모필드 = in.readXXX(); // 부모 객체의 필드값을 읽어옴
..
in.defaultReadObject(); // 자식 객체의 필드값을 역직렬화
}
두 메서드를 작성할 때 주의점은 접근 제한자가 private이 아니면 자동 호출 되지 않기 때문에 반드시 private를 붙여주어야한다.
writeObject()와 readObject() 메서드의 매개값인 ObjectOutputStream과 ObjectInputStream은 다양한 종류의 writeXXX(),readXXX() 매서드를 제공하므로 부모 필드 타입에 맞는 것을 선택해서 사용하면 된다.
defaultWriteObject()와 defaultReadObject()는 자식 클래스에 정의된 필드들을 모두 직렬화하고 역직렬화한다.
데코레이터 패턴 - java.io
출처: https://alkhwa-113.tistory.com/entry/IO [기(술) 블로그]
- java.io 패키지는 데코레이터 패턴으로 만들어졌다.
- 데코레이터 패턴이란, A 클래스에서 B 클래스를 생성자로 받아와서, B 클래스에 추가적인 기능을 덧붙여서 제공하는 패턴이다.
//BufferedReader 클래스
private Reader in;
public BufferedReader(Reader in) {
this(in, defaultCharBufferSize);
}
- BufferedReader 는 Reader 의 하위 클래스중 하나를 받아와서, 버퍼를 이용한 기능을 추가한 기능을 제공한다.
- BufferedReader 처럼 출력을 담당하는 래퍼 클래스는 출력을 하는 주체가 아니라 도와주는 역할이다.
- Stream 을 사용한 클래스들에서 이렇게 도와주는 클래스들을 보조 스트림이라 한다.
출처:
이것이 자바다
https://www.notion.so/I-O-af9b3036338c43a8bf9fa6a521cda242
I/O
WhiteShip Java Study 시즌 1
www.notion.so
https://alkhwa-113.tistory.com/entry/IO
I/O
선장님과 함께하는 자바 스터디입니다. 자바 스터디 Github github.com/whiteship/live-study whiteship/live-study 온라인 스터디. Contribute to whiteship/live-study development by creating an account on..
alkhwa-113.tistory.com
https://bingbingpa.github.io/java/whiteship-live-study-week13/
자바 I/O
자바 I/O Feb 11, 2021 Java whiteship/live-study java java I/O whiteship/live-study 13주차 정리 목표 학습할 것 (필수) 스트림 (Stream) / 버퍼 (Buffer) / 채널 (Channel) 기반의 I/O InputStream 과 OutputStream Byte 와 Character
bingbingpa.github.io
https://b-programmer.tistory.com/268
I/O
I/O 입력과 출력을 뜻하는 용어로, 입출력은 컴퓨터 내부 또는 외부의 장치와 프로그램간의 데이터를 주고받는 것을 말한다. 스트림/버퍼/채널 스트림 스트림은 흐름이라는 뜻을 가지고 있다.(람
b-programmer.tistory.com
'스터디 > 백기선 라이브 스터디(자바)' 카테고리의 다른 글
| 15주차 과제: 람다식 (0) | 2021.06.05 |
|---|---|
| 14주차 과제: 제네릭 (0) | 2021.06.01 |
| 12주차 과제: 애노테이션 (0) | 2021.03.05 |
| 11주차 과제: Enum (0) | 2021.03.05 |
| 10주차 과제: 멀티쓰레드 프로그래밍 (0) | 2021.02.25 |


